You are here: TDI Users>Integrator Web>LearningTDI>HowTo>FlatFileLookups (10 Feb 2012, AndrewFindlay)
Flat File Lookups
You have two flat files (CSV, LDIF, XML...) containing lists of people and you need to work out which entries match and which are different or missing. You cannot do a lookup in a CSV file, so how do you solve the problem? This is the basis of an exercise that I often set for students on TDI training courses. It is a very common thing to have to do in the early stages of a synchronisation project where you have several databases that are supposed to be in sync but may not be. If you can do lookups directly on the real databases then the job is easy, but often you only get given CSV files or similar so what are the choices? Let's assume that we have a CSV file and an LDIF file, and we want to find which entries from the LDIF are missing or changed in the CSV.Load into a database
The obvious solution is to load the CSV file into a database so that you can do easy lookups. This needs two assembly-lines: one to load the CSV data and one to iterate through the LDIF file doing lookups. If you have serious amounts of unsorted data this is probably the best solution.Simulate lookup using a loop
You could re-open the CSV file for every item that you want to lookup, and iterate until you find the match or fall off the end. This is quite easy to do, but it has dreadful scaling properties: the work increases in proportion to the square of the number of entries when comparing two files of similar sizes. OK for 100 entries (the loop iterator will run about 5000 times) but not so good for 10,000 entries (the loop will run about 50,000,000 times!).Store the CSV data in memory
If the data will fit in memory then this could be very effective. We need a data structure that supports efficient lookups, so a simple array is not going to help. If working in Perl I would simply load the CSV data into a hash (associative array) using an appropriate field as the index value. TDI does not use Perl, but this set me to wondering whether something similar might be done in JavaScript. Well it turns out that JavaScript objects can be used as associative arrays, by making use of object properties:var csvData = new Object; csvData['fred'] = 'Bloggs'; csvData['tommy'] = 'Atkins';That gives us a form of key-value database entirely in memory. The next problem is that we cannot use separate assembly lines to load and to compare the data, as the memory is not transferable between them. We could read the CSV file in an assembly-line prolog hook, but that is wasting much of the power of TDI.
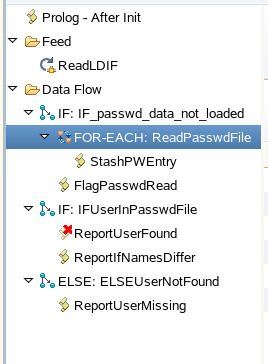 My favourite solution so far is to 'lazy load' the data.
Rather than trying to create the lookup table in the prolog, this assembly line
dives straight into iterating through the LDIF.
When it is about to do the first lookup it checks to see whether the lookup table
actually exists. If not then it runs a connector loop to load it before carrying on.
My favourite solution so far is to 'lazy load' the data.
Rather than trying to create the lookup table in the prolog, this assembly line
dives straight into iterating through the LDIF.
When it is about to do the first lookup it checks to see whether the lookup table
actually exists. If not then it runs a connector loop to load it before carrying on.
To complete the solution, there is an AL Prolog hook that declares the object:
var passwd = new Object;...and a script to stash each entry read by the connector loop:
passwd[work.getString("pw_nam")] = [
work.getString("pw_nam"),
work.getString("pw_passwd"),
work.getString("pw_uid"),
work.getString("pw_gid"),
work.getString("pw_gecos"),
work.getString("pw_home"),
work.getString("pw_shell"),
];
The FlagPasswordRead script simply sets a variable that is tested by the
IF_passwd_data_not_loaded conditional.
Here is the assembly line: save it as a local file then cut-n-paste it into the
Assembly Lines folder of a TDI config editor.
I have also provided a sample CSV file (actually a Unix-style password file
so it is colon-separated) and a sample LDIF to try it out with.
You can read more about objects as associative arrays on Quirksmode.
-- AndrewFindlay - 09 Feb 2012
Topic revision: r2 - 10 Feb 2012, AndrewFindlay
- This page was cached on 26 Jun 2025 - 09:13.


Ideas, requests, problems regarding TDI Users? Send feedback